Deep Web
Se le conoce informalmente como Internet profunda o Internet invisible (Deepweb, Invisible Web, Deep Web, Dark Web o Hidden Web) a una porción presumiblemente muy grande de la Internet que es difícil de rastrear o ha sido hecha casi imposible de rastrear y deliberadamente, como lo es el caso del Proyecto Tor, caso en el cuál ha sido hecha de ésta manera usando métodos de routing no convencionales, cómo con la proxyficación con muchos proxys, el no utilizar direcciones de Internet, sino códigos y el utilizar el pseudónimo .onion, la cuál fue creada por la Armada de Estados Unidos como una prueba y ahora es utilizada por el usuario común.
La internet profunda es un conjunto de sitios web y bases de datos que buscadores comunes no pueden encontrar ya que no están indexadas. El contenido que puede ser hallado dentro de la Internet profunda es inmenso.
Se estima que la Internet Profunda es 500 veces mayor que la Internet Superficial, y que el 95% es públicamente accesible. Se suele representar a la Deep Web como la parte de una iceberg que está por debajo del nivel del agua (siendo la parte superficial del iceberg la web de uso público).

El internet se ve dividido en dos ramas, la internet profunda y la superficial. El Internet Superficial se compone de páginas estáticas o fijas, mientras que Web profunda está compuesta de páginas dinámicas. La páginas estáticas no dependen de una base de datos para desplegar su contenido sino que residen en un servidor en espera de ser recuperadas, y son básicamente archivo HTML cuyo contenido nunca cambia. Todos los cambios se realizan directamente en el código y la nueva versión de la página se carga en el servidor. Estas páginas son menos flexibles que las páginas dinámicas. Las páginas dinámicas se crean como resultado de una búsqueda de base de datos. El contenido se coloca en una base de datos y se proporciona sólo cuando lo solicite el usuario.
La principal causa de la existencia de la Internet profunda es la imposibilidad de los motores de búsqueda (Google, Opera, Yahoo, por ejemplo) de encontrar o indexar gran parte de la información existente en Internet. Si los buscadores tuvieran la capacidad para acceder a toda la información entonces la magnitud de la “Internet profunda” se reduciría casi en su totalidad.
Para entender esta carencia es necesario conocer el funcionamiento actual de la mayoría de los buscadores. Cuando una persona realiza una consulta, el buscador no recorre la totalidad de Internet en busca de las posibles respuestas, lo cual supondría una capacidad de reacción bastante lenta. Lo que hace es buscar en su propia base de datos, que ha sido generada e indizada previamente. En sus labores de búsqueda, indización y catalogación, utilizan las llamadas “arañas” o robots inteligentes que van saltando de una página web a otra siguiendo los enlaces de hipertexto y registran la información allí disponible.
El problema aparece cuando la información requerida se encuentra en una página que carece de enlaces. En este caso, la única forma que tiene de ser registrada en un buscador, es que su autor la incluya manualmente rellenando un formulario. En caso contrario, esta web resultará invisible para todos aquellos usuarios de Internet que no conozcan la URL o dirección concreta.
Sin embargo, si una página carece de enlaces, no es la única causa que puede llevar a una web a permanecer en las profundidades, invisible a los buscadores generalistas. Éstos suelen indexar páginas estáticas que incluyen textos simples y que están programadas en HTML, el lenguaje de programación más común. Ésta es la información que, sin ninguna duda, un usuario encontraría en la llamada Red superficial utilizando los buscadores más comunes, y buena parte del resto pasa a formar parte de la Red profunda.
Por último, en la deep web se puede hallar todo tipo de cosas ya que los usuarios son completamente anónimos. Desde pornografía infantil y pornografía gore muy intensa, venta de drogas, hackers, piratas informáticos, supuestos sicarios, venta de información, etc. hasta instrucciones de fabricación de armas nucleares. Por otro lado se pueden encontrar también periodistas, notas o información que de otro modo sería de muy difícil acceso o censuradas. Una de las redes mas conocidas en este sentido es Wikileaks, quienes desarrollan una versión no censurable de Wikipedia para la publicación masiva y el análisis de documentos secretos, manteniendo a sus autores en el anonimato, filtrando información desde capas muy profundas de internet. Entrar en la deepweb está bajo la responsabilidad del usuario.
A continuación una serie de links a tener en cuenta (tenga precaución y sea responsable del uso de esta información):
- Link de película sobre la deep web: http://www.deepwebthemovie.com/
- Link sobre cómo acceder a la deep web: http://www.neoteo.com/como-acceder-a-la-deep-web-con-tor/
- Link a Tor Proyect: https://www.torproject.org/
- Link de directorios: http://thehiddenwiki.org/
- Link de directorios: https://zarza.com/internet-profunda-deep-web/
En esta entrada

Aaron Koblin
Aaron Koblin, (USA, 1982). Es un artista americano de medios digitales, principalmente conocido por el uso innovador de la visualización de datos y su trabajo pionero en el crowdsourcing y el cine interactivo. Actualmente es co-fundador y CTO de Vrse, un portal
Aaron Koblin
Aaron Koblin, (USA, 1982). Es un artista americano de medios digitales, principalmente conocido por el uso innovador de la visualización de datos y su trabajo pionero en el crowdsourcing y el cine interactivo. Actualmente es co-fundador y CTO de Vrse, un portal

Wikileaks
Wikileaks desarrolla una versión no censurable de Wikipedia para la publicación masiva y el análisis de documentos secretos (“Leaks”), manteniendo a sus autores en el anonimato. Su creador es Julian Assange (Austalia, 1971) y está gestionado por The Sunshine Press. Su slogan: Abrimos
Wikileaks
Wikileaks desarrolla una versión no censurable de Wikipedia para la publicación masiva y el análisis de documentos secretos (“Leaks”), manteniendo a sus autores en el anonimato. Su creador es Julian Assange (Austalia, 1971) y está gestionado por The Sunshine Press. Su slogan: Abrimos

Art Hack Day
Art Hack Day (Día del Arte del Hack) es una organización sin fines de lucro con base en Internet dedicada a los piratas informáticos (hackers) cuyo medio es el arte y a los artistas cuyo medio es lo tecnológico. El
Art Hack Day
Art Hack Day (Día del Arte del Hack) es una organización sin fines de lucro con base en Internet dedicada a los piratas informáticos (hackers) cuyo medio es el arte y a los artistas cuyo medio es lo tecnológico. El

ARPANET
La red de computadoras Advanced Research Projects Agency Network (ARPANET) fue creada por encargo del Departamento de Defensa de los Estados Unidos como medio de comunicación para los diferentes organismos del país. El primer nodo se creó en la Universidad
ARPANET
La red de computadoras Advanced Research Projects Agency Network (ARPANET) fue creada por encargo del Departamento de Defensa de los Estados Unidos como medio de comunicación para los diferentes organismos del país. El primer nodo se creó en la Universidad

Visualización de Datos
La visualización de datos es visto por muchas disciplinas como un equivalente moderno de la comunicación visual. No es propiedad de algun campo especifico, sino más bien se encuentra bajo la interpretación a través de muchas disciplinas (por ejemplo, es
Visualización de Datos
La visualización de datos es visto por muchas disciplinas como un equivalente moderno de la comunicación visual. No es propiedad de algun campo especifico, sino más bien se encuentra bajo la interpretación a través de muchas disciplinas (por ejemplo, es

Hipertexto
Hipertexto: Sistema que permite que un texto contenga enlaces con otras secciones de un documento o con otros documentos. Por ejemplo “http” significa “protocolo de transferencia para hipertexto”. Ted Nelson, en 1965, fue el primero en acuñar la palabra “hypertext”,
Hipertexto
Hipertexto: Sistema que permite que un texto contenga enlaces con otras secciones de un documento o con otros documentos. Por ejemplo “http” significa “protocolo de transferencia para hipertexto”. Ted Nelson, en 1965, fue el primero en acuñar la palabra “hypertext”,

Tor project
Tor es un software libre y una red abierta que ayuda a defenderse contra el análisis de tráfico como forma de vigilancia que amenaza la libertad personal y la privacidad, confidencialidad en los negocios y las relaciones, y la seguridad
Tor project
Tor es un software libre y una red abierta que ayuda a defenderse contra el análisis de tráfico como forma de vigilancia que amenaza la libertad personal y la privacidad, confidencialidad en los negocios y las relaciones, y la seguridad

WWW
En informática, la World Wide Web (WWW) o Red informática mundial es un sistema de distribución de información basado en hipertexto o hipermedios enlazados y accesibles a través de Internet. Con un navegador web, un usuario visualiza sitios web compuestos
WWW
En informática, la World Wide Web (WWW) o Red informática mundial es un sistema de distribución de información basado en hipertexto o hipermedios enlazados y accesibles a través de Internet. Con un navegador web, un usuario visualiza sitios web compuestos

Photogrammar
Photogrammar es una plataforma basada en la web para organizar, buscar y visualizar las 170.000 fotografías del período 1935 a 1945 tomadas por diferentes fotógrafos en comisión del Gobierno de los Estados Unidos y su agencia de Seguridad Agrícola y
Photogrammar
Photogrammar es una plataforma basada en la web para organizar, buscar y visualizar las 170.000 fotografías del período 1935 a 1945 tomadas por diferentes fotógrafos en comisión del Gobierno de los Estados Unidos y su agencia de Seguridad Agrícola y
Wikipedia
Wikipedia es una enciclopedia libre, políglota y editada colaborativamente. Es administrada por la Fundación Wikimedia, una organización sin ánimo de lucro. Sus más de 37 millones de artículos en 284 idiomas (cantidad que incluye dialectos de muchos de esos idiomas)
Wikipedia
Wikipedia es una enciclopedia libre, políglota y editada colaborativamente. Es administrada por la Fundación Wikimedia, una organización sin ánimo de lucro. Sus más de 37 millones de artículos en 284 idiomas (cantidad que incluye dialectos de muchos de esos idiomas)

Chrome Experiments
Google Chrome Experiments es una sala de exposición en línea de experimentos basados en navegador web, códigos de programación interactivos, y proyectos artísticos. Lanzado en marzo de 2009, Google Chrome Experiments es un sitio web oficial de Google que fue originalmente
Chrome Experiments
Google Chrome Experiments es una sala de exposición en línea de experimentos basados en navegador web, códigos de programación interactivos, y proyectos artísticos. Lanzado en marzo de 2009, Google Chrome Experiments es un sitio web oficial de Google que fue originalmente

Historia de la información
http://www.historyofinformation.com/ “Mientras los siglos continúan desarrollándose, el número de libros crecerá continuamente, y uno puede predecir que llegará un momento en que va a ser casi tan difícil de aprender cualquier cosa de los libros a partir del estudio directo
Historia de la información
http://www.historyofinformation.com/ “Mientras los siglos continúan desarrollándose, el número de libros crecerá continuamente, y uno puede predecir que llegará un momento en que va a ser casi tan difícil de aprender cualquier cosa de los libros a partir del estudio directo
Distinta Categoría

Morphing
Un morphing, es un efecto especial que utiliza la animación por computadora para transformar la imagen fotográfica de un objeto real en la imagen fotográfica de otro objeto real. Se lo utiliza sobre todo para crear la ilusión de la transformación
Morphing
Un morphing, es un efecto especial que utiliza la animación por computadora para transformar la imagen fotográfica de un objeto real en la imagen fotográfica de otro objeto real. Se lo utiliza sobre todo para crear la ilusión de la transformación

A Computer Animated Hand
A Computer Animated Hand, 1972, animación digital 3D realizada por Ed Catmull y Fred Parke en la Universidad de Utah, USA. El video resultó ser un referente en el desarrollo de la animación por ordenador y posteriormente se incorporó en
A Computer Animated Hand
A Computer Animated Hand, 1972, animación digital 3D realizada por Ed Catmull y Fred Parke en la Universidad de Utah, USA. El video resultó ser un referente en el desarrollo de la animación por ordenador y posteriormente se incorporó en
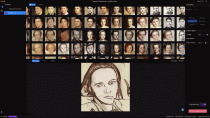
RunwayML
RunwayML es un software que hace accesible técnicas de Machine Learning sin necesidad de saber código. Es el desarrollo de la tesis de Cristóbal Valenzuela en la Tisch School of the Arts de la Universidad de Nueva York, siendo lanzada
RunwayML
RunwayML es un software que hace accesible técnicas de Machine Learning sin necesidad de saber código. Es el desarrollo de la tesis de Cristóbal Valenzuela en la Tisch School of the Arts de la Universidad de Nueva York, siendo lanzada

La estética lúdica en el arte participativo en Brasil
Arte, tecnología y ciencia mantienen una relación tricotómica más fuerte de lo que podría pensarse. Desde el contexto histórico brasileño, Claudia Giannetti, siguiendo las teorías y pensamientos de Vilém Flusser, realiza un análisis detallado de los cruces entre el trabajo creativo
La estética lúdica en el arte participativo en Brasil
Arte, tecnología y ciencia mantienen una relación tricotómica más fuerte de lo que podría pensarse. Desde el contexto histórico brasileño, Claudia Giannetti, siguiendo las teorías y pensamientos de Vilém Flusser, realiza un análisis detallado de los cruces entre el trabajo creativo

Eder Santos
Eder Santos, Brasil, 1960. Trabaja en video arte y video instalaciones. Es uno de los mas reconocidos artistas de video de Sur América. Eder Santos crea vibrantes obras poéticas, que funden lo personal, lo cultural y lo tecnológico para reinterpretar
Eder Santos
Eder Santos, Brasil, 1960. Trabaja en video arte y video instalaciones. Es uno de los mas reconocidos artistas de video de Sur América. Eder Santos crea vibrantes obras poéticas, que funden lo personal, lo cultural y lo tecnológico para reinterpretar
Hipertexto
Hipertexto: Sistema que permite que un texto contenga enlaces con otras secciones de un documento o con otros documentos. Por ejemplo “http” significa “protocolo de transferencia para hipertexto”. Ted Nelson, en 1965, fue el primero en acuñar la palabra “hypertext”,
Hipertexto
Hipertexto: Sistema que permite que un texto contenga enlaces con otras secciones de un documento o con otros documentos. Por ejemplo “http” significa “protocolo de transferencia para hipertexto”. Ted Nelson, en 1965, fue el primero en acuñar la palabra “hypertext”,

Kimsooja
Kimsooja es una artista surcoreana cuyas principales obras exploran el video y la video instalacion, trascendiendo las fronteras entre el uso de acciones reiteradas y procesos de meditacion . Muchas de sus obras comprenden acciones cotidianas, tales como lavar la
Kimsooja
Kimsooja es una artista surcoreana cuyas principales obras exploran el video y la video instalacion, trascendiendo las fronteras entre el uso de acciones reiteradas y procesos de meditacion . Muchas de sus obras comprenden acciones cotidianas, tales como lavar la

Visions of America
Visions of America, proyección en tiempo real de data en conjunto con una performance musical. La obra fue realizada en 2014 por el artista Refik Anadol, (Turquia, 1985), transformando así el espacio que entraba en díalogo junto con la
Visions of America
Visions of America, proyección en tiempo real de data en conjunto con una performance musical. La obra fue realizada en 2014 por el artista Refik Anadol, (Turquia, 1985), transformando así el espacio que entraba en díalogo junto con la

Fotografía Infrarroja
La fotografía infrarroja es una técnica que nos permite captar un espectro lumínico que no es visible para el ojo humano, comprendido entre 700 y 1200 nanómetros. Tiene sus orígenes en el año 1910 en los Estados Unidos, con fotografías
Fotografía Infrarroja
La fotografía infrarroja es una técnica que nos permite captar un espectro lumínico que no es visible para el ojo humano, comprendido entre 700 y 1200 nanómetros. Tiene sus orígenes en el año 1910 en los Estados Unidos, con fotografías

Francis Alys
Francis Alys, (Bélgica, 1959). Artista multidisciplinario, trabaja en performance, video, animación, instalaciones y fotografía. Su obra surge en el espacio interdisciplinario del arte, la arquitectura y la práctica social y trata sobre migraciones, política global, lo urbano y procesos sociales
Francis Alys
Francis Alys, (Bélgica, 1959). Artista multidisciplinario, trabaja en performance, video, animación, instalaciones y fotografía. Su obra surge en el espacio interdisciplinario del arte, la arquitectura y la práctica social y trata sobre migraciones, política global, lo urbano y procesos sociales